
Clinical Outcome Assessment Testing: Which Rater Training Method Is Most Effective?
By Michael Calcagni, DPT, and Brandon Lum, DPT, Clinical Assessment Solutions

The methodological flaws of a study can determine the success or failure of a clinical trial. For trials that utilize clinical outcome assessments (COAs) as their study endpoints, rater training is paramount in ensuring data integrity by improving inter-rater reliability. The consequences of inadequate rater training can be detrimental to these studies, potentially resulting in increased measurement error and data variance, significant increases in study costs,1 and the potential of incorrectly failed trials.2 Trials utilizing COAs have significant testing variability concerns to address, including varying degrees of rater education, experience, and proficiency and the standardization of the testing protocol among multiple sites,3 in potentially multiple countries with different languages and cultures.4,5 The challenge is to address these variables and to effectively train all the raters to administer the same scale, the same way, at every visit, for every patient.
Effective rater training is integral for these studies, as many rely on data obtained from clinical judgement to measure patient improvement.6 Rater-administered subjective assessments and observational/performance tests have a degree of subjectivity that make them far more susceptible to interpretation, human error, and data fluctuations than trials that utilize objective laboratory measured changes. In order to demonstrate consistent and reliable data, a confluence of processes in multiple areas of clinical trial design, implementation, and training must be standardized. Processes like rater training must be considered with meticulous scrutiny, as it plays such a critical role in ensuring accurate data to demonstrate a drug’s efficacy.
With the rising use of COAs as endpoints in clinical trials, rater training methods must be more highly analyzed in order to ensure consistent testing administration to obtain the most reliable data. This need is particularly apparent in rare disease trials where study sample sizes are limited due to small subject enrollment, and every data set becomes increasingly valuable to power the study.
Many studies have confirmed the need for rater training,6-12 but few have examined different methods of training under empirical evaluation to determine their effectiveness. Our study evaluated three different training methods to ascertain which method resulted in the lowest inter-rater variability and testing administration error.
Physical therapy doctoral graduate students were randomly divided into three training groups: in person, remote, and video. Each group was trained on a customized clinical assessment tool comprised of elements from validated patient reported outcome (PRO) and clinician reported outcome (ClinRo) assessment tests. The in-person group was trained live, in person with the opportunity to physically practice the examination components. The remote group was trained via live video conferencing with the opportunity to virtually practice the examination components. The video group was provided a training video that outlined the testing protocol and described all testing procedures. The video group was given full access to the video until their testing assessment. For testing assessments, the same scripted mock patient was used to create consistent responses and ensure grading consistency by a blinded reviewer. All groups were video recorded administering the customized clinical assessment tool to the same scripted mock patient. The video recording of each testing assessment was evaluated remotely and asynchronously by a blinded expert reviewer to independently score each test, assess the standardization of testing protocol, identify scoring discrepancies, and identify testing errors.
Across all tests, the video group scored substantially lower (more errors) compared to a blinded expert and with higher variability than the remote group and the in-person group. The mean scores (± SD) for the video group on the PRO and ClinRO were 31% (± 40%) and 55% (± 14%), respectively. The mean scores for the remote group on the PRO and ClinRO were 80% (± 21%) and 90% (± 9%), respectively. The mean scores for the in-person group on the PRO and ClinRO were 88% (± 13 and 91% (± 4%), respectively. The video group demonstrated the most scoring inconsistency at ± 27%, the remote group demonstrated ± 15%, and the in-person group demonstrated the least scoring deviation at ± 8.5%.
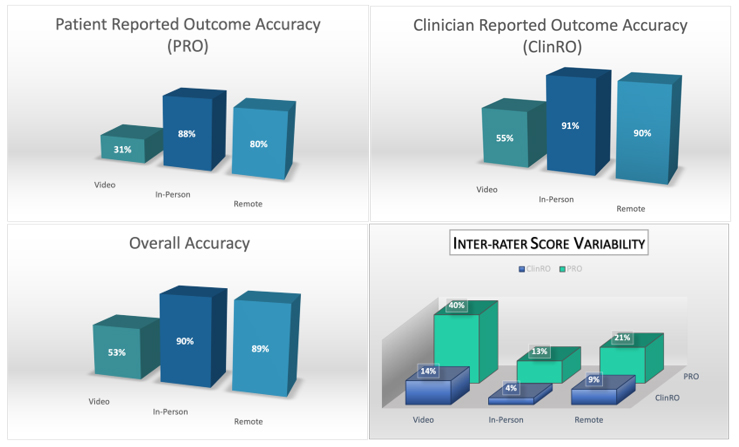
The method of rater training can have significant impact on rater reliability and data accuracy in clinical trials that utilize COAs to assess efficacy. This study illustrates that the raters who participated in live synchronous or in-person training demonstrated the best inter-rater variability (± 8.5%) and the greatest score accuracy (90%). Live synchronous remote training was also effective, demonstrating comparably low inter-rater variability (± 15%) and high score accuracy (89%). However, asynchronous video training was the most inferior mode of training, as this group demonstrated the worst inter-rater variability (± 27%) and the lowest accuracy score (53%).
With the rising use of COAs as endpoints in clinical trials, sponsors should be more critical of rater training methodology to decrease measurement error and data variance. Live training, whether via in person or remote video, was significantly more effective than asynchronous video training in executing the standardized administration of the testing protocol. With the number of variables affecting data integrity in clinical trials, live synchronous in-person and live synchronous remote training should be highly considered over asynchronous video training as part of a rater training program for clinical trials.
References
- Cogger, K. O. (2007). Rating rater improvement. Journal of Clinical Psychopharmacology, 27(4), 418–420. https://doi.org/10.1097/01.jcp.0000280315.81366.f8
- Khan A, Yavorsky WC, Liechti S, DiClemente G, Rothman B. Assessing the sources of unreliability (rater, subject, time-point) in a failed clinical trial using items of the Positive and Negative Syndrome Scale (PANSS). J Clin Psychopharmacol. 2013 Feb;33(1):109-17
- Small, G., Schneider, S., Hamilton, A., Bystritsky, A., Meyers, B., Nemeroff, C., (1996). Site variability in a multisite geriatric depression trial. International Journal of Geriatric Psychiatry, 11(12), 1089–1095.
- Keefe, R.S.E. and P.D. Harvey, Implementation Considerations for Multisite Clinical Trials with Cognitive Neuroscience Tasks. Schizophrenia Bulletin, 2008. 34(4): p. 656-663.
- Miller, J., Complex Clinical Trials are Posing New Challenges Across the Clinical Supply Chain. BioPharm International, 2010. 23(4).
- Hansen, T., Elholm Madsen, E., & Sørensen, A. (2015). The effect of rater training on scoring performance and scale-specific expertise amongst occupational therapists participating in a multicentre study: A single-group pre–post-test study. Disability and Rehabilitation, 38(12), 1216–1226. https://doi.org/10.3109/09638288.2015.1076069
- Busner, J., A. Kott, and G. Sachs, Increasing signal over noise in MDD clinical trials: improvement after efficacy scale rater training among experienced MDD investigators. European Neuropsychopharmacology, 2013. 23: p. S348-S348.
- Kobak, K.A., et al., A new approach to rater training and certification in a multicenter clinical trial. J Clin Psychopharmacol, 2005. 25(5): p. 407-12.
- Rosen, J., et al., Web-based training and interrater reliability testing for scoring the Hamilton Depression Rating Scale. Psychiatry Research, 2008. 161(1): p. 126-130.
- Schuld, C., et al., Effect of formal training in scaling, scoring and classification of the International Standards for Neurological Classification of Spinal Cord Injury. Spinal Cord, 2013. 51(4): p. 282-288.
- Tabuse, H., et al., The new GRID Hamilton Rating Scale for Depression demonstrates excellent inter-rater reliability for inexperienced and experienced raters before and after training. Psychiatry Research, 2007. 153(1): p. 61-67.
- Targum, S.D., Evaluating rater competency for CNS clinical trials. J Clin Psychopharmacology, 2006. 26(3): p. 308-10.
- US Food and Drug Administration. [Accessed July 3, 2021]; Clinical outcome assessment (COA): glossary of terms. 2016
- US Food and Drug Administration. [Accessed July 3, 2021]; Guidance for industry: patient-reported outcome measures: use in medical product development to support labeling claims. 2009
- Walton MK, Powers JH, III, Hobart J, et al. Clinical outcome assessments: conceptual foundation—Report of the ISPOR Clinical Outcomes Assessment—Emerging Good Practices for Outcomes Research Task Force. Value Health. 2015; 18:741–52.
- Becker, R.E., N.H. Greig, and E. Giacobini, Why do so many drugs for Alzheimer’s disease fail in development? Time for new methods and new practices? J Alzheimers Dis, 2008. 15(2): p. 303-25.
- English, R., Y. Lebovitz, and R. Griffin, Transforming Clinical Research in the United States: Challenges and Opportunities: Workshop Summary, in Forum on Drug Discovery.
About the Authors:
 Brandon Lum is co-founder of Clinical Assessment Solutions and a Doctor of Physical Therapy specializing in neuromuscular disease and orthopedics as a board-certified orthopedic clinical specialist (OCS). He is an experienced rater trainer in pharmaceutical clinical research in training clinical evaluators on clinical outcome assessment (COA) administration in clinical trials. He has led clinical evaluator (CE) training at site initiation visits (SIV), national and international investigator meetings (IMs), and remote video rater training sessions for global neuromuscular disease trials. He has created alternate asynchronous training materials for clinical trials, including CE training manuals, certification documentation, and training videos.
Brandon Lum is co-founder of Clinical Assessment Solutions and a Doctor of Physical Therapy specializing in neuromuscular disease and orthopedics as a board-certified orthopedic clinical specialist (OCS). He is an experienced rater trainer in pharmaceutical clinical research in training clinical evaluators on clinical outcome assessment (COA) administration in clinical trials. He has led clinical evaluator (CE) training at site initiation visits (SIV), national and international investigator meetings (IMs), and remote video rater training sessions for global neuromuscular disease trials. He has created alternate asynchronous training materials for clinical trials, including CE training manuals, certification documentation, and training videos.
 Michael Calcagni is co-founder of Clinical Assessment Solutions and a Doctor of Physical Therapy specializing in orthopedics and neuromuscular diseases. He has been involved with clinical research as a consultant and clinical evaluator trainer on Phase 2 and Phase 3 rare neuromuscular disease trials. He has coordinated and led national and international investigator meetings (IMs) and has consulted on script development and production of clinical outcome assessment training videos for site resources.
Michael Calcagni is co-founder of Clinical Assessment Solutions and a Doctor of Physical Therapy specializing in orthopedics and neuromuscular diseases. He has been involved with clinical research as a consultant and clinical evaluator trainer on Phase 2 and Phase 3 rare neuromuscular disease trials. He has coordinated and led national and international investigator meetings (IMs) and has consulted on script development and production of clinical outcome assessment training videos for site resources.