
Data Interoperability: The First Step To Leverage ML & AI In Clinical Trials
By Kamila Novak, KAN Consulting

For decades, the drug development industry has accumulated enormous amounts of data from clinical trials and observational studies. The quantity keeps growing exponentially and is being enriched with data coming, nowadays, mostly from electronic sources, such as electronic case report forms (eCRF), wearables, electronic patient-reported outcomes (ePRO), electronic clinical outcome assessments (eCOA), electronic informed consents (eICF), new digital biomarkers, etc. Recently, we started unlocking rich sources of real-world data (RWD) that can provide more accurate insights into the patient journey. These are data from claims databases, hospital records, mortality data, disease registries, consumer data, pharmacy records, laboratory and biomarker databases, and even social media.
With more and more data available in almost real time, we see the potential to make insightful decisions, speed up drug development, and increase the success rate of new therapies. Machine learning (ML) and artificial intelligence (AI) used in other industries have found their way to the drug development field, thanks to their ability to work with large data sets effectively, efficiently, and much faster than humans. ML and AI algorithms have already been used successfully in finding new potentially effective substances and are starting to expand to clinical trials, safety management, submission management, and electronic document management and archiving.
Data Interoperability
The first hurdle we need to overcome to leverage ML and AI is data interoperability. We must break data silos, find a way to make the data points communicate with one another within the drug development continuum, and analyze each data point in its full context. This is easier said than done. Data are coming from different sources, in different formats, including structured, semi-structured, and unstructured, with different levels of trust in their reliability depending on their provenance. We cannot forget appropriate governance, security, privacy protection, and ownership, which tends to be rather complex across multiple stakeholders.
Let’s imagine we want to conduct a clinical trial (Figure 1). Click on figure to enlarge.

Our initial considerations regarding the protocol design are based on our preclinical and clinical data, historical data from our previous studies, published results of studies conducted by other sponsors, known information about the drug class, discussions with statisticians, clinicians, patients, and regulators, and possibly real-world evidence (RWE).
Once our trial starts, we collect data from the eICF application, eCRF, risk-based monitoring (RBM) module, ePRO, eCOA, interactive response technology (IRT), clinical trial management system (CTMS), medical imaging, laboratories, and so on and so forth; this not an all-inclusive list. All study data should eventually end up in the electronic trial master file (eTMF) and electronic archive, ensuring digital preservation. Trials using 10 to 15 different systems are not unusual.
To make things even more complex, let’s imagine we use a synthetic control arm (SCA) that combines data from previous randomized clinical trials (RCTs) and RWD-RWE. It is easy to get lost in this maze. Without data interoperability, we cannot get timely analyses that give us insights to make the right decision at the right time.
Perhaps we aim to achieve a good diversity of recruited patients to resemble the target patient population that will use our drug once marketed. In real time, we need to know the profile of each patient being recruited in each participating study site and country and make the right Stop – Go decisions for the desired representation (Figure 2). Data management is turned into data science.
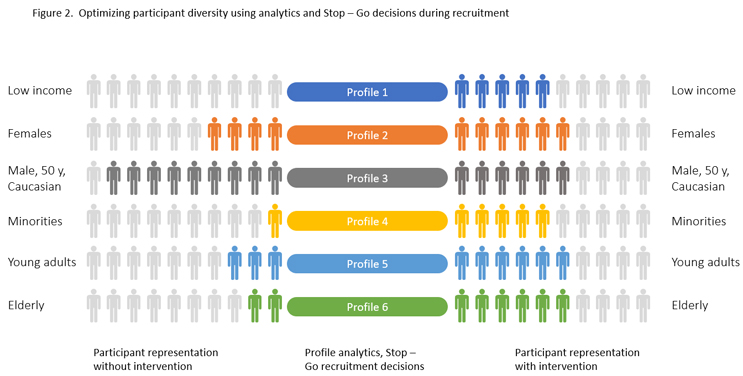
The Importance Of Metadata
When talking about data interoperability, we should not forget the role of metadata. In simple terms, metadata is “data about data”, such as means of creation, purpose, time and date of creation, creator or author, location on a computer network where the data was created, standards used, file size, data quality, source, and process to create them. We can say that metadata give context to each data item.
Why is the context so important? It is essential for correct understanding what the data item means.
Let’s make an analogy in human language and take the word “date.” Does it have one unique meaning? No, it does not. It can mean different things depending on the context.
- “You must not date my daughter!” shouts a furious father of a 16-year-old at a married man in his late 40s.
- “What date is it today?” “Please pencil the date in your agenda so as not to miss this appointment.”
- “Should I date my signature?”
Without context, we do not know if it is a noun or a verb, if we look at the angry father or a calendar.
In clinical trials, metadata help implement CDISC standards and accelerate the study reporting process, allow different people to access, monitor, track, and log data, help ensure our data are high quality. If we store metadata in a dedicated well-designed repository, we have a practical way to work with the data again later after the study was closed.
In addition, in open-access settings (yes, we fulfill transparency expectations), metadata can be re-used by other researchers for additional data analyses and help gain further insights.
How Do We Achieve Data Interoperability?
There are different ways to achieve data interoperability.
One approach advocates unified data formats. If all data are in the same format, disparate data silos can easily merge into one large data lake or warehouse. Is this feasible? Technically, perhaps yes, at a limited scale, in such settings as one small company. Across the industry globally? Unlikely. Even in one large company it can be a daunting task. Did you feel the clinical trial example was a bit overwhelming? Then add other company data from manufacturing, submissions for marketing authorizations, sales, pharmacovigilance, and regulatory affairs, and the headache gets intense.
There are many data formats; new ones are emerging and creating one unified format may result in losing important properties or attributes. Have you ever heard of Esperanto? Yes, the artificial language created by the Polish ophthalmologist L. L. Zamenhof in 1887, intended to be a universal second language for international communication. After almost 135 years, it has not achieved this goal. We can dive into a philosophical debate about why, however, this is not our topic today. I think that any artificial language is likely simplistic, and nuances of natural languages get lost, which then affects understanding of the spoken word and effective communication. The same can happen if we convert one data format into another. The other aspect is that we still need the data at the primary point of use (typically, where the data is generated), so moving them into a central data lake while ensuring access by all who need to work with the data poses additional challenges.
Instead of a unifying data format, we can use an application programming interface (API) to access the data. The API is placed as an overlay above all data silos or data-generating systems; it “talks” to each of them, works with metadata, uses all data without moving them out of their respective systems, and feeds analytical software and ML and AI applications. APIs are system agnostic and do not care about data formats (Figure 3). Click on figure to enlarge.
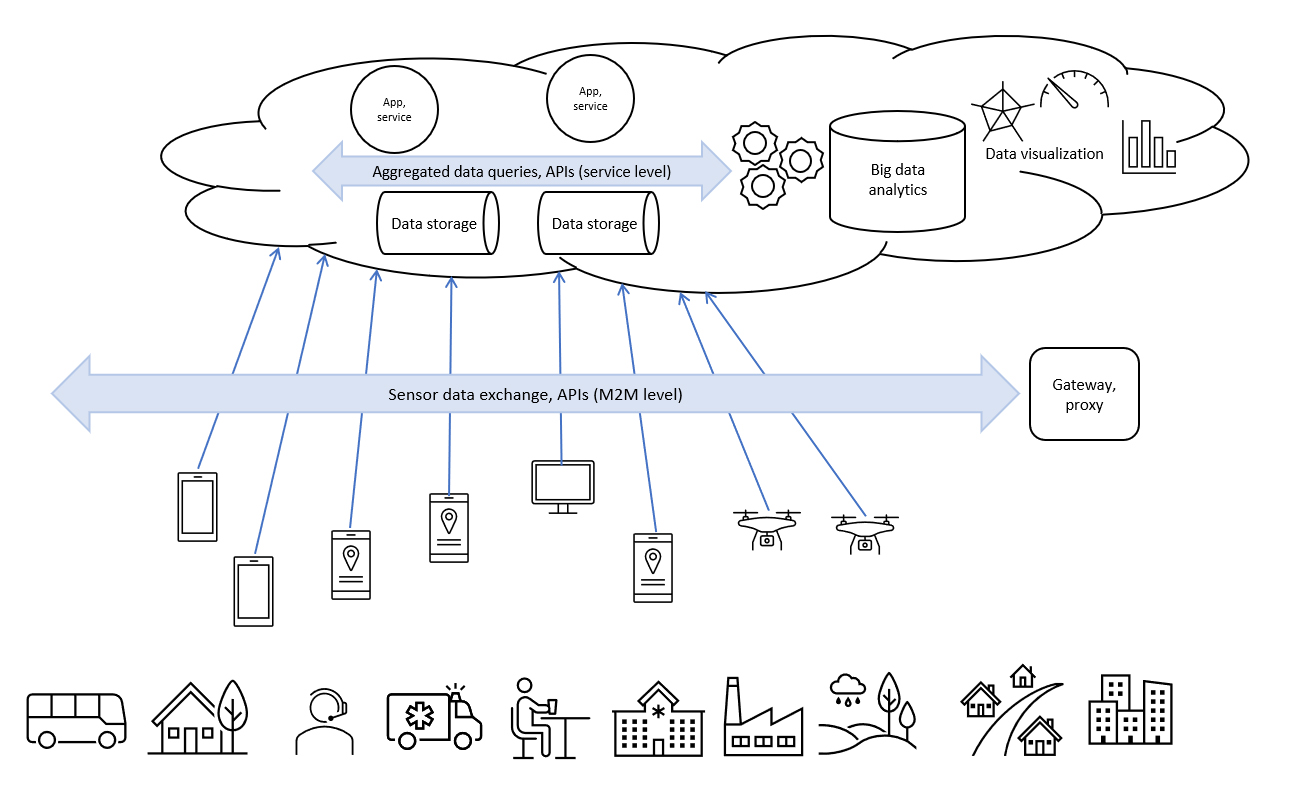
Our other possibility is to implement a federated database. Very much like how independent states form a federation to become one country, we can combine autonomous data stores into one virtual federated database or data store (Figure 4).
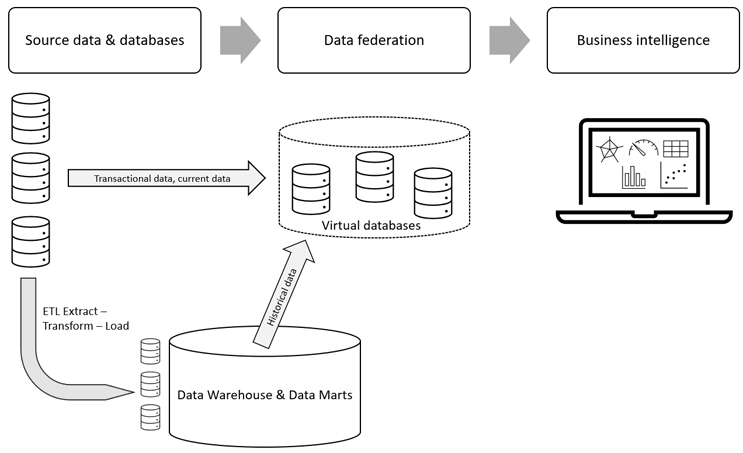
The advantage of data federation is that it enables us to bring together data from data stores that use different storage structures, different access languages, and different APIs. As a data consumer using data federation, we can access different types of database servers and files with various formats, integrate data from all those sources, transform the data, and access the data through various APIs and languages.1 Data federation is part of data virtualization, which includes metadata repositories, data abstraction, read and write access to source data systems, and advanced security.2
Now let’s imagine we want to work with medical imaging data and teach our AI-enhanced application to analyze these data and give up new insights. To do this, we need a very millions of images from different hospitals taken by different cameras since deep learning algorithms are stacked in a hierarchy of increasing complexity and abstraction. Deep learning resembles the way the human brain learns. Due to privacy protection, we cannot take the image data from the hospitals and pool them in one large database. Data federation will help us to design federated learning working with data without moving them out of the hospitals.3, 4
If we work with very large data sets in a global company, we can consider an end-to-end data integration and management solution that will help us have all the data organized and accessible. This is what data fabric and/or data mesh do for us.
Data fabric consists of architecture, data management and integration software, and shared data, which provides a unified, consistent user experience and access to data for any company member worldwide in real time.2 Data fabrics creates relationships across various metadata points within disparate and even disconnected data sources allowing creation of and following specific relationship maps. In the healthcare data landscape, we can link patient care patterns in localized electronic medical records (EMR) with geographically specific pharmacy claims data and with overlapping physician registry information by zip code. It gives us the possibility to map specific physician-patient diagnosis and treatment with direct cost of care by treatment center and location. The specific connectivity between the disparate data sources does not have to be common data elements, or primary keys, such as in a data warehouse, but rather common metadata patterns that can be mapped or linked into a relational “fabric” across the differential data landscape. Figure 5 shows a simplified diagram of data fabric.
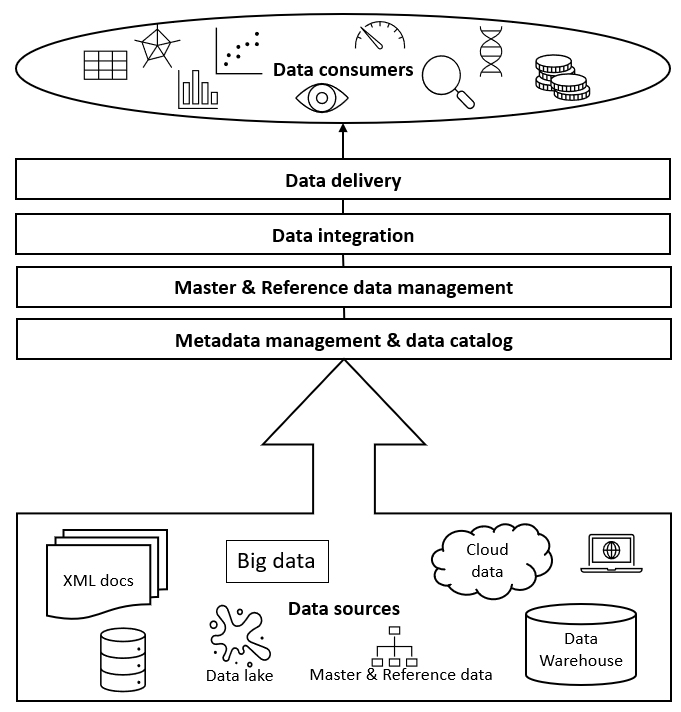
Data mesh, like data fabric, aims to overcome the hurdle of managing data in a heterogeneous environment. However, it uses a different approach. It is an API-driven solution encouraging distributed groups of teams to manage data as they see fit, with some common governance provisions.5
Which Approach Is The Best?
There is no universal answer, and one size does not fit all. We should consider the questions we want to get answered, the size of our company, the return on investment, our strategic goals, how fit for our purpose each approach is, the scalability of different technology solutions, etc. We should choose solutions that can grow with our business.
Vision Of The Future
Like Clinerion’s vision of SMART hospitals,6 I envision SMART companies using insights from their data as well as RWD to find new effective and safe therapies, conduct inclusive SMART trials, and reduce new therapy costs and time to market. So many patients are waiting. With the increasing requirements for transparency and open access to data, I hope to see growing collaboration in the pharmaceutical industry. Development of therapies against COVID-19 demonstrated it is possible.
References:
- Rick F. van der Lans, Data Virtualization for Business Intelligence Systems, 2012
- TIBCO® Reference Center. Accessed on 07 Nov 2021.
- Woodie A. Data Mesh Vs. Data Fabric: Understanding the Differences. Datanami, A Tabor Communications Publication. October 25, 2021
- Sarma KV, Harmon S, Sanford T, Roth HR, Xu Z, Tetreault J, Xu D, Flores MG, Raman AG, Kulkarni R, Wood BJ, Choyke PL, Priester AM, Marks LS, Raman SS, Enzmann D, Turkbey B, Speier W, Arnold CW. Federated learning improves site performance in multicenter deep learning without data sharing. J Am Med Inform Assoc. 2021 Jun 12;28(6):1259-1264. doi: 10.1093/jamia/ocaa341. PMID: 33537772; PMCID: PMC8200268.
- Xu, J., et al. (2019) Federated Learning for Healthcare Informatics. arXiv:1911.06270 https://ui.adsabs.harvard.edu/abs/2019arXiv191106270X
- Drake D, The Clinerion Technology Vision for RWD Insights - Enabling a full digital patient profile from EHR to enhance physician access, clinical research, and patient care, Clinerion White Paper, October 2021, available at: https://www.clinerion.com/index/OverviewNews/WhitePapersAndCaseStudies/ClinerionTechnology
Vision.html
About The Author:
 Kamila Novak, MSc, got her degree in molecular genetics. Since 1995, she has been involved in clinical research in various positions in pharma and CROs. Since 2010, she has been working as an independent consultant focusing on QA and QC, as a certified auditor for several ISO standards, risk management, medical writing, and training. She is a member of the Society of Quality Assurance (SQA), the World Medical Device Organisation (WMDO), the European Medical Writers’ Association (EMWA), the Drug Information Association (DIA), the Continuing Professional Development (CPD) UK, and other professional societies.
Kamila Novak, MSc, got her degree in molecular genetics. Since 1995, she has been involved in clinical research in various positions in pharma and CROs. Since 2010, she has been working as an independent consultant focusing on QA and QC, as a certified auditor for several ISO standards, risk management, medical writing, and training. She is a member of the Society of Quality Assurance (SQA), the World Medical Device Organisation (WMDO), the European Medical Writers’ Association (EMWA), the Drug Information Association (DIA), the Continuing Professional Development (CPD) UK, and other professional societies.