
Is Double Programming Really Required For Validation?
By Sunil Gupta, CDISC, SAS, and R SME, trainer, and author

Double programming has long been considered the gold standard for validation, but technological advancements and improved sponsor oversight of CRO deliverables have introduced more efficient and reliable alternatives. This article examines the challenges of double programming and explores alternative methods to validate study data tabulation models (SDTMs), analysis data models (ADaMs), and tables, listings, and graphs (TLGs). The discussion outlines the original objectives of double programming and new methods that better align with modern regulatory requirements.
The Role And Evolution Of Double Programming In Clinical Trials For Validation
Deliverables in clinical trials are created from a data management process that consists of subsetting, conditions, algorithms, summaries, and joins. Each component and step in this process is critical and needs to be performed correctly and completely. Quality control (QC) steps ensure a structured checklist and logical order execution to prevent sequence failures.
Because clinical trials are so expensive, sponsors have developed methods to eliminate risks associated with producing incorrect results. Thirty years ago, the only practical method to achieve this was to double program and compare the results. In today’s world, with advancements in best practices and technology, the relevance of double programming is increasingly questioned.
In principle, double programming works by comparing the outputs of two programmers, with any inconsistencies or errors identified and resolved to ensure the accuracy and reliability of the final outputs. In general, discrepancies arise when either the primary or secondary SAS (statistical analysis system) programmer forgot to apply a condition or a specification detail.
While many organizations continue to use two SAS programmers for double programming, R packages (a set of functions in a programming language for statistical computing and data visualization) are increasingly used to reproduce SDTMs. Tidyverse, a collection of common R packages, can be used for multiple tasks, while Pharmaverse and other R packages adopted by organizations must be internally validated before moving into production.
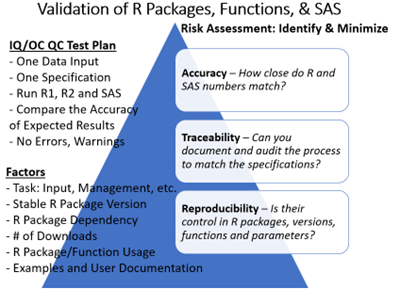
Current Solutions To Validate SDTMs And ADaMs
Today’s process of transforming raw data into SDTM and ADaM formats involves multiple structured steps. These include applying standard names, units, and control terminology, creating required variables, renaming variables, converting dates to ISO 8601 character format, removing all user-defined formats, and establishing paired and hierarchical variables. Additional steps involve ordering variables, sorting records, converting data into a vertical structure, creating supplemental domains when needed, assigning unscheduled visits, and, finally, conducting checks for SDTM and ADaM inconsistencies or data issues.
For variable derivations, multiple raw variables may be combined into a single SDTM variable or, conversely, a single raw variable may be split into separate SDTM variables. To ensure consistent control terminology transformation from raw to SDTM, a format catalog is often created and applied using the PUT() function, rather than relying on multiple IF-THEN statements, which can become cumbersome and prone to error.
Most SAS macro systems and tools provide predefined templates that automate some of this process. These templates can save programming time and improve standardization across studies. However, they come with inherent limitations in terms of traceability and validation. Since SAS macros and programs often call multiple subprograms, achieving a complete end-to-end view of variable derivation can be challenging.
With the increasing adoption of R and the Pharmaverse ecosystem, new open-source packages have been designed and validated to create SDTMs and ADaMs more efficiently. Rather than building isolated SAS-based workflows, forward-thinking organizations can jumpstart their SDTM and ADaM processes using packages like OAK and Admiral, which require minimal customization.
CROs that support sponsors in developing these Pharmaverse-based solutions may be required to use OAK and Admiral for SDTM and ADaM transformations, rather than relying on their own custom SAS macros or internal systems. Many other Pharmaverse packages continue to be co-developed by industry subject matter experts (SMEs), including sponsors, CROs, PHUSE, and regulatory agencies.
Despite these advancements, many organizations still require a second SAS programmer to validate all their programs. While up to 80% of SDTM domains are standardized and could be automated with minimal validation efforts, the remaining 20% of non-standard SDTMs or complex variable derivations still require double programming.
Some organizations have introduced risk-based validation levels to determine the most appropriate validation strategy. For instance, visual verification may be used for reviewing a single SDTM program to confirm team alignment and maintain an audit trail of variable derivations. Programmatic reviews of outputs can be employed to check consistency between raw and SDTM vitals, while visual reviews of outputs ensure that clinical results are aligned with expectations.
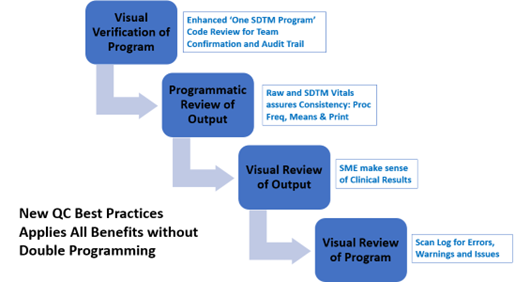
Why Eliminate Double Programming For SDTM And ADaM?
Although double programming has long been the gold standard for validation, advancements in technology and regulatory guidance have shown that it is unnecessary. In fact, even though the FDA requires sponsors to submit SDTMs, ADaMs, and TLGs, they do not mandate how this validation should be performed.
In other words, double programming is not a regulatory requirement.
Instead, the FDA encourages a risk-based approach, allowing organizations to tailor their validation strategies based on the complexity of the study, the level of risk, and available technology.
By using, for example, validated SDTM and ADaM macros, organizations have decreased the risk of producing incorrect SDTMs and ADaMs; however, mistakes are still made. Some of these practices emphasize leveraging metadata from all available sources to ensure consistency and accuracy. For example, SDTM IG metadata provides predefined standards for variable order, names, lengths, types, labels, and sorting rules for each domain, reducing the potential for inconsistencies.
Despite these advancements, many organizations continue to document variable specifications in English sentences or pseudo-code, introducing potential inconsistencies. To ensure alignment, metadata vitals — such as frequency counts, unique and missing values of categorical variables, and means and ranges of continuous variables — must be checked across raw data and SDTMs. These vitals should be consistent across all data categories, including demographics, treatments, vitals, medical history, exposure, labs, adverse events (AEs), and concomitant medications.
By shifting away from rigid double programming requirements and embracing new approaches of validation, organizations can enhance efficiency while maintaining — or even improving — data accuracy and regulatory compliance.
SAS Tools And Traceability-Powered AI System Alternatives To Double Programming
For the first time, organizations can improve their validation process with targeted validation powered by code traceability-driven AI systems. These systems provide a new level of transparency, empowering SAS programmers in their development and QC processes. Code is no longer just a tool for data transformation — it now serves as an input to metadata, improving organization, categorization, and analysis, and ultimately giving programmers a deeper understanding of the data. Additionally, AI enables more advanced processing and querying of large data sets, leading to faster and more reliable insights.
Since double programming is not a regulatory requirement, sponsors should adopt alternative validation methods. A fit-for-purpose approach to SDTM and ADaM validation should focus on two key questions: Do the results make sense? Are they consistent? While excessive data checks may seem beneficial, they often yield diminishing returns, consuming resources without significantly improving validation quality.

The Good Clinical Practice Guide outlines several acceptable validation approaches for statistical programming, including:
- independent programming (dual programming and output comparison)
- detailed output checks against raw data or data listings, combined with code review (essentially, system validation)
- use of previously validated code or macros
- retention and review of statistical software logs to confirm correct execution
- verification of new variables and datasets derived from final data management outputs
- review of formulae in spreadsheets, where applicable.
With traceability-powered AI systems, statistical programmers gain full transparency across raw, SDTM, and ADaM variables, along with code, SDTM IG, ADaM IG, and variable mapping specifications. These systems allow programmers to trace each variable derivation from specification to raw data, through SDTMs, and into ADaMs, ensuring complete visibility before deploying SAS programs into production. A dashboard provides a visual representation of all related SAS programs, automatically linking them together so that every step in the data management process can be monitored in real time. This significantly reduces manual effort, eliminating the need for programmers to search through and manually piece together transformation logic across multiple SAS programs and macros.
By replacing double programming with traceability-driven validation, organizations can ensure SDTM and ADaM compliance with confidence while freeing resources to focus on more complex tasks and additional clinical studies. However, statistical programmers must continue to adhere to high standards in program design and unit testing to maintain data integrity. Best practices include coding based on SOPs, deep knowledge of clinical data, self-QC against specifications, and comprehensive process documentation. Throughout development, programmers should actively address validation and debugging issues, including missing values, special characters, invalid syntax, and logical inconsistencies in code.
Benefits Of Traceability-Powered AI Systems
While this article has primarily focused on eliminating double programming for SDTMs, the same approach can be extended to ADaMs and TLGs. Since SDTMs are a regulatory requirement, they serve as an ideal starting point for automation and validation improvements. Once SDTMs are streamlined, the same structured workflow can be applied to ADaMs and TLGs, as these data sets build upon SDTMs and rely on multiple SAS programs and macros for processing.
Beyond eliminating double programming, AI-driven enhancements provide additional efficiencies in clinical trial review, preparation, and analysis. These tools improve oversight and management of CRO deliverables, reducing unnecessary manual validation of SDTMs while maintaining compliance.
From a quality control perspective, AI-powered traceability systems enhance the review of not just the adherence to specifications but also of SAS logs, ensuring that outputs are free from critical errors, warnings, and key notes, such as uninitialized values, data conversions, invalid arguments, missing values, mathematical inconsistencies, and merge conflicts. By integrating traceability-powered AI tools, even the most risk-averse sponsors can confidently replace double programming with a structured, systematic validation approach, reducing redundancy while improving accuracy.
Below is a list of benefits of a traceability-powered AI dashboard for complete traceability between SDTM IG, variable specifications, raw data, SDTMs, and ADaMs.
- Link all related code into a single SDTM and ADaM program.
- Cross-reference specifications to identify gaps and ensure clarity in variable definitions.
- Map all raw data to SDTM and ADaM variables.
- Ensure comprehensive mapping of required SDTM domains and variables, including TA, DM, EX, DS, SRCDOM, and SRCVAR.
- Track variable derivations from raw to SDTM and ADaM using frequency counts, means, and ranges.
- Monitor code lists, frequency counts, and missing values to maintain data consistency.
- Identify invalid metadata or control terminology for non-extensible SDTM and ADaM variables.
- Track patient populations, subjects, and records across raw data, SDTMs, and ADaMs (e.g., ensuring IE ≥ DM ≥ EX > DV/AE/DS).
- Ensure compliance with protocol requirements, such as dose, visits, cycles, phases, indications, exposure, and disposition.
- Monitor primary and secondary efficacy measures and lab events across raw, SDTM, and ADaM data sets.
- Track treatment-emergent AEs, hospital events, standardized medical queries (SMQs), deaths, and serious adverse events (SAEs).
- Monitor demographic and subgroup vital metrics, including sex, age, race, populations, strata, treatments, and studies.
- Track primary reasons for discontinuation across raw, SDTMs, and ADaMs.
- Monitor updates to raw data throughout the study life cycle.
Smarter organizations with strong leadership in the industry are already moving beyond double programming. They recognize that they are not alone in this shift and that more efficient alternatives are readily available. Now is the time to challenge outdated validation practices and embrace modern technology-driven approaches.
References:
- Achieve faster and higher-quality submission, Verisian White Paper. https://sassavvy.com/resources/SAS%20Downloads/Verisian%20Booklet.pdf
- Double Programming: a Critical Perspective. https://www.linkedin.com/posts/richardusvonk_double-programming-a-critical-perspective-activity-7287073712531496962-tS-c/
- AI’s Influence on SAS Programming. https://cytel.com/perspectives/ais-influence-on-sas-programming/?utm_campaign=5731914-2025%20blog&utm_content=324078854&utm_medium=social&utm_source=linkedin&hss
_channel=lcp-54577 - AI in Clinical Trials: Achieving Meaningful Automation. https://www.linkedin.com/feed/update/urn:li:activity:7300220854200680449
- Artificial Intelligence for Drug Development. https://www.fda.gov/about-fda/center-drug-evaluation-and-research-cder/artificial-intelligence-drug-development
- Determining a risk-proportionate approach to the validation of statistical programming for clinical trials. https://pmc.ncbi.nlm.nih.gov/articles/PMC10865752/#bibr3-17407745231204036
- Eliminating SDTM Double Programming by using a Validation Tool & Dummy Data. https://phuse.s3.eu-central-1.amazonaws.com/Archive/2024/Connect/US/Bethesda/PAP_DH02.pdf
- Automating SDTM: A Metadata-Driven Journey. https://pharmasug.org/proceedings/2023/MM/PharmaSUG-2023-MM-205.pdf
- Should We Still Be Using Trackers For Clinical Trial Management? Donatella Ballerini, TMF Consultant, Clinical Leader. https://www.clinicalleader.com/doc/should-we-still-be-using-trackers-for-clinical trial-management-0001?
About The Expert:
 Sunil Gupta, MS, is a strategic advisor to a traceability-powered AI platform, as well as an international speaker, best-selling author of five SAS books and a global SAS/R developer and CDISC SME and corporate trainer. Sunil is an advocate of CDISC automation and standardization with over 30 years of experience in the pharmaceutical industry. Most recently, Sunil is teaching Practical R for SAS programmers and a CDISC online class at the University of California at San Diego at UCSD Extension. In 2019, Sunil published his fifth book, “Clinical Data Quality Checks for CDISC Compliance Using SAS,” and in 2011, Sunil launched his unique SAS mentoring blog, SASSavvy.com, for smarter SAS searches and R-Guru.com for R self-study class and mentoring programming. Sunil has an MS in bioengineering from Clemson University and a BS in applied mathematics from the College of Charleston.
Sunil Gupta, MS, is a strategic advisor to a traceability-powered AI platform, as well as an international speaker, best-selling author of five SAS books and a global SAS/R developer and CDISC SME and corporate trainer. Sunil is an advocate of CDISC automation and standardization with over 30 years of experience in the pharmaceutical industry. Most recently, Sunil is teaching Practical R for SAS programmers and a CDISC online class at the University of California at San Diego at UCSD Extension. In 2019, Sunil published his fifth book, “Clinical Data Quality Checks for CDISC Compliance Using SAS,” and in 2011, Sunil launched his unique SAS mentoring blog, SASSavvy.com, for smarter SAS searches and R-Guru.com for R self-study class and mentoring programming. Sunil has an MS in bioengineering from Clemson University and a BS in applied mathematics from the College of Charleston.