
Safe And Scalable AI Deployment For Clinical Trials
By Partha Anbil and Partha Khot

National and international regulatory actions 1,2,3 acknowledge the urgency of establishing guardrails for the use of AI. However, these instruments focus on transparency, reporting standards, and ethical principles rather than offering a practical, stepwise road map for implementation. Major existing frameworks4,5,6 each address important dimensions of the AI life cycle, yet none provide a comprehensive, phased implementation strategy that mirrors the rigor clinical research professionals expect from any new intervention. Life sciences organizations have access to an expanding arsenal of AI tools, but they lack a structured, evidence-based methodology for moving these tools from pilot projects to scaled, safe, and effective clinical deployment.
A Clinical Trials-Informed Approach
A compelling new perspective proposes a solution rooted in one of medicine’s most trusted paradigms: the clinical trials process.10 Developers Jacqueline G. You, Tina Hernandez-Boussard, Michael A. Pfeffer, Adam Landman, and Rebecca G. Mishuris advocate for a clinical trials-informed framework that adapts the four phases of clinical research to the pragmatic deployment of AI in healthcare systems at scale. The American Medical Informatics Association has taken a similar approach with case studies of AI12, underscoring the growing consensus around structured implementation.
The clinical research process is well understood by industry professionals: Phase 1 evaluates safety in small populations; Phase 2 measures efficacy and identifies side effects in hundreds of individuals; Phase 3 conducts larger-scale benefit monitoring relative to the standard of care; and Phase 4 involves post-market surveillance in thousands of individuals.13 By mapping these established phases onto AI implementation, the framework provides a familiar, structured pathway that systematically addresses regulatory compliance, patient safety, model validation, equity, and scalability. Importantly, this framework applies to AI solutions not necessarily classified as medical devices — it includes pragmatic consideration of clinical workflows in the informatics realm, making it universally applicable to both in-house developed tools and vendor-based solutions.
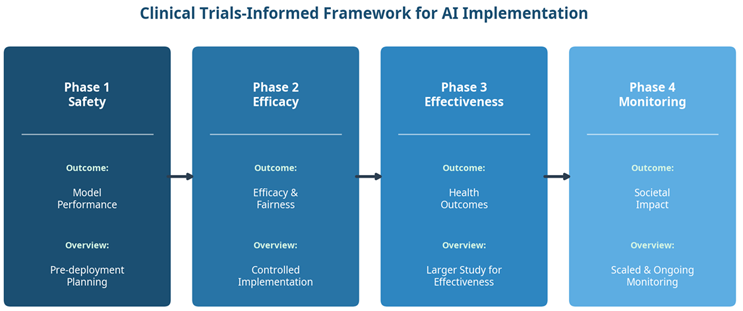
Figure 1. The four-phase clinical trials-informed framework for AI implementation in healthcare.
The Four Phases In Detail
Phase 1: Safety — Laying the Foundation
The first phase focuses on pre-deployment planning and preparation, assessing the foundational safety of the AI model or tool. Models are deployed in a controlled nonproduction setting where they exert no influence on clinical decisions. Testing can be conducted retrospectively — using historical EHR data, for instance — or in “silent mode,”14 where the AI generates predictions that are observed by the implementation team but remain invisible to clinicians and patients.
Key activities during this phase include engaging diverse stakeholders from the outset, comparing training populations with target populations to identify gaps in model applicability, developing strategies to prioritize underserved populations, designing initial clinical workflows, and conducting bias and fairness analyses using retrospective data.
A practical example involves using a large language model for clinical trial screening by evaluating retrospective EHR notes to determine patient eligibility without risking patient outcomes.15 This phase may also include validation analysis across different patient demographics to ensure the model does not inadvertently disadvantage specific groups.16
Phase 2: Efficacy — Controlled Real-World Testing
The second phase transitions from retrospective evaluation to prospective, controlled implementation. The model’s efficacy is examined under ideal conditions by integrating it into live clinical environments with limited visibility by clinical staff. Models typically run in the background, processing real-world data without impacting clinical decision-making until performance is thoroughly vetted.
During this phase, teams organize data pipelines to ensure hospital data flows into the model correctly and identify which team members — nurses, physicians, pharmacists — will act on data output at specific steps in clinical workflows. Standards and thresholds for monitoring are established, and the model is evaluated prospectively with blind predictions. Efficacy and fairness are assessed across subpopulations, and the impact on quality, efficiency, and financial outcomes is measured as anticipatory work essential ahead of scaling.
Real-world examples include AI systems that predict emergency department admission rates with results hidden from end users to refine accuracy17 and an AI-based acute coronary syndrome detection tool that used real-world data ingestion to optimize equity and fairness.18,19,20.
Phase 3: Effectiveness — Broader Deployment and Comparative Assessment
Phase 3 marks the transition from controlled efficacy testing to broader effectiveness evaluation. The AI tool is deployed across multiple clinical settings, and its performance is assessed relative to current standards of care. The distinction between efficacy and effectiveness is critical: While Phase 2 measures outcomes under ideal circumstances, Phase 3 measures benefit in pragmatic, real-world settings, twenty-one incorporating health outcome metrics that demonstrate tangible impact on patient care and clinician workflows. Implementation teams evaluate the model’s generalizability by evaluating it across diverse patient populations, measuring geographic and domain-specific performance.
A compelling example is the ambient documentation platform piloted by Stanford and Mass General Brigham across multiple clinical specialties, which converts patient-clinician conversations into draft clinical notes reviewed and edited before EHR entry. Note quality is compared to clinician-written notes, while clinician experience and burnout are rigorously assessed. Another example involves AI-generated inbox draft replies,22,23 where efficiency gains and quality metrics such as professionalism and tone are evaluated beyond traditional process outcomes.24

Phase 4: Monitoring — Sustained Surveillance at Scale
The final phase addresses one of the most critical yet often overlooked aspects of AI deployment: ongoing post-deployment surveillance. AI tools require continuous monitoring to track performance, safety, and equity over time, ensuring models are recalibrated as they evolve or face data shifts. The integration of monitoring systems into routine workflows allows for rapid identification of adverse events or bias. Systems to detect model drift25 can inform updates or de-implementation of ineffective solutions. The authors draw on methodologies from traditional clinical decision support, including override comments as feedback mechanisms26 and the Vanderbilt Clickbusters initiative, which iteratively reviews clinical alerts to optimize their utility.7 Machine learning operations (MLOps) practices, broad dissemination of findings, development of training programs, and feedback loops for clinical teams are all essential during this phase.
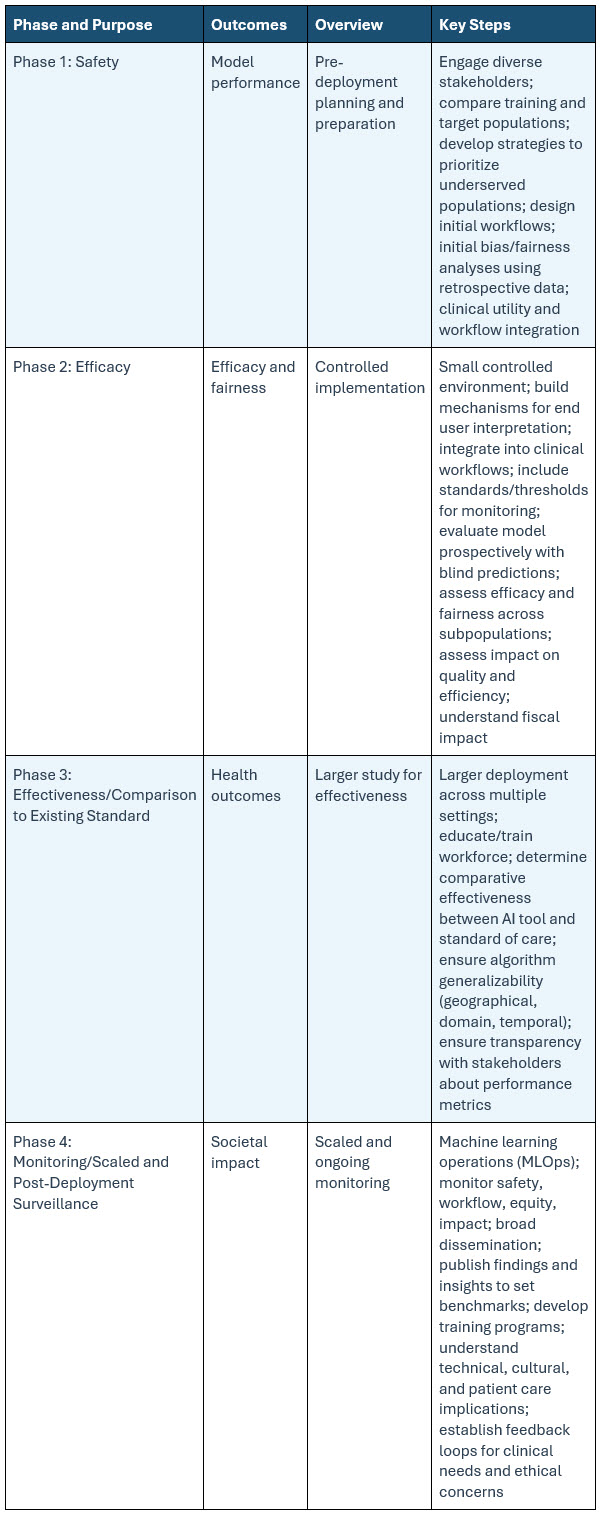
Table 1: Clinical Trials Framework For AI Applications
Regulatory Landscape And Financial Viability
The regulatory environment for healthcare AI varies significantly across jurisdictions. In the U.S., healthcare organizations can deploy in-house AI models without FDA certification, allowing significant flexibility for internal clinical use. This contrasts sharply with other jurisdictions where most clinical AI tools must be certified before use. Addressing such regulatory variation is essential for the framework’s global applicability, balancing flexibility for internal use with structured validation for external deployment.
Financial viability is embedded into the framework’s early phases. Cost considerations extend well beyond the initial technical investment in building the AI solution to encompass uptake, staff training, trust-building with communities regarding safe and equitable healthcare AI applications, and ongoing maintenance. These costs must be weighed against return on investment and factored alongside pragmatic and patient-oriented outcomes to justify testing and scaling the technology. This discipline prevents unnecessary reiteration of pilots that do not yield scalable, financially tenable solutions.
The Imperative Of Inter-Institutional Collaboration
The authors advocate strongly for broad stakeholder engagement, governmental support including NIH funding, and industry sponsorship to systematically study AI technologies across healthcare systems. Organizations such as the Coalition for Health AI (CHAI), the MIT Task Work on the Work of the Future,28 and the Ambient Clinical Documentation Collaborative exemplify the inter-institutional collaboration needed to share lessons and best practices.8 Mass General Brigham and Stanford are both part of CHAI, and Mass General Brigham participates in the Ambient Clinical Documentation Collaborative, a group of academic medical centers sharing insights on ambient documentation. While AI clinical trials are more likely to occur at larger academic medical centers given the required resources and technical expertise, it is crucial that lessons learned are disseminated to community healthcare centers and safety net hospitals, ensuring all populations benefit.9
Implications For Industry Professionals
For professionals working in pharmaceutical research, this framework offers several actionable takeaways. It provides a common language and structured methodology aligned with the clinical trials paradigm, facilitating more productive conversations between AI developers, clinical stakeholders, regulatory bodies, and payers. The framework’s emphasis on equity and fairness at every phase reflects the growing recognition that AI tools must serve all patient populations, not just those well-represented in training data. For organizations evaluating vendor-based AI tools, the phased approach provides a structured due diligence process adaptable to local institutional needs while maintaining rigorous safety and effectiveness standards. The integration of financial viability into early planning ensures that implementation efforts are grounded in practical sustainability, not just technological possibility.
Conclusion
By adapting the trusted phased methodology of clinical research to the unique challenges of healthcare AI, the framework provides a pragmatic, structured, and scalable pathway from pilot to production. It addresses the full spectrum of implementation concerns — from foundational safety and controlled efficacy testing to broad effectiveness evaluation and sustained post-deployment monitoring — while embedding equity, fairness, and financial viability as core considerations throughout. As industry continues to grapple with the promise and complexity of AI, frameworks like this one offer a much-needed bridge between innovation and responsible deployment.
References:
- European Parliament. EU AI Act: first regulation on artificial intelligence. 2024. Available at: https://www.europarl.europa.eu/topics/en/article/20230601STO93804/eu-ai-act-first-regulation-on-artificial-intelligence
- The White House. Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. 2023.
- Office of the National Coordinator for Health Information Technology. Health Data, Technology, and Interoperability: Certification Program Updates, Algorithm Transparency, and Information Sharing. 45 CFR § 170, 171. 2024.
- Ishizaki K. AI model lifecycle management: overview. IBM. 2020. Available at: https://www.ibm.com/think/topics/ai-lifecycle
- Cruz Rivera S, Liu X, Chan A-W, Denniston AK, Calvert MJ. Guidelines for clinical trial protocols for interventions involving artificial intelligence: the SPIRIT-AI extension. Lancet Digit Health. 2020;2: e549-e560.
- Liu X, Cruz Rivera S, Moher D, Calvert MJ, Denniston AK. Reporting guidelines for clinical trial reports for interventions involving artificial intelligence: the CONSORT-AI extension. Lancet Digit Health. 2020;2: e537-e548.
- McCoy AB, et al. Clinician collaboration to improve clinical decision support: the Clickbusters initiative. J Am Med Inform Assoc. 2022; 29:1050-1059.
- Coalition for Health AI (CHAI). Our Purpose. 2024. Available at: https://chai.org/our-purpose/
- Longhurst CA, Singh K, Chopra A, Atreja A, Brownstein JS. A call for artificial intelligence implementation science centers to evaluate clinical effectiveness. NEJM AI. 2024.
- You JG, Hernandez-Boussard T, Pfeffer MA, Landman A, Mishuris RG. Clinical trials informed framework for real world clinical implementation and deployment of artificial intelligence applications. npj Digital Medicine. 2025; 8:107. Available at: https://doi.org/10.1038/s41746-025-01506-4
- Mesko B, Görög M. A short guide for medical professionals in the era of artificial intelligence. npj Digital Medicine. 2020; 3:126.
- American Medical Informatics Association. AMIA 2024 Artificial Intelligence Evaluation Showcase. 2024. Available at: https://amia.org/education-events/amia-2024-artificial-intelligence-evaluation-showcase
- Food and Drug Administration. Step 3: clinical research. FDA. 2018. Available at: https://www.fda.gov/patients/drug-development-process/step-3-clinical-research
- Nestor B, et al. Preparing a clinical support model for silent mode in general internal medicine. In Proceedings of the 5th Machine Learning for Healthcare Conference. PMLR. 2020; 126:950-972.
- Unlu O, et al. Retrieval-augmented generation–enabled GPT-4 for clinical trial screening. NEJM AI. 2024;1: AIoa2400181.
- De Hond AAH, et al. Perspectives on validation of clinical predictive algorithms. npj Digital Medicine. 2023; 6:86.
- Dadabhoy FZ, et al. Prospective external validation of a commercial model predicting the likelihood of inpatient admission from the emergency department. Ann Emerg Med. 2023; 81:738-748.
- Bunney G, et al. Beyond chest pain: Incremental value of other variables to identify patients for an early ECG. I am J Emerg Med. 2023; 67:70-78.
- Callahan A, et al. Standing on FURM ground: a framework for evaluating fair, useful, and dependable AI models in healthcare systems. NEJM Catalyst. 2024;5:CAT.24.0131.
- Röösli E, Bozkurt S, Hernandez-Boussard T. Peeking into a black box, the fairness and generalizability of a MIMIC-III benchmarking model. Scientific Data. 2022; 9:24.
- Agency for Healthcare Research and Quality. Criteria for Distinguishing Effectiveness from Efficacy Trials in Systematic Reviews. 2006. Available at: https://www.ncbi.nlm.nih.gov/books/NBK44029/
- Achiam OJ, et al. GPT-4 Technical Report. 2023. Available at: https://doi.org/10.48550/arXiv.2303.08774
- Garcia P, et al. Artificial intelligence–generated draft replies to patient inbox messages. JAMA Network Open. 2024;7: e243201.
- Small WR, et al. large language model–based responses to patients' in-basket messages. JAMA Network Open. 2024;7: e2422399.
- Davis SE, Greevy RAJ, Lasko TA, Walsh CG, Matheny ME. Detection of calibration drift in clinical prediction models to inform model updating. J Biomed Informatics. 2020; 112:103611.
- Aaron S, McEvoy DS, Ray S, Hickman T-TT, Wright A. Cranky comments detecting clinical decision support malfunctions through free-text override reasons. J Am Med Inform Assoc. 2019; 26:37-43.
- National Association of Community Health Centers & American Academy of Family Physicians. Closing the Primary Care Gap: How Community Health Centers Can Address the Nation's Primary Care Crisis. 2023. Available at: https://www.nachc.org/wp-content/uploads/2023/06/Closing-the-Primary-Care-Gap_Full-Report_2023_digital-final.pdf
- MIT Work of the Future. About Us. 2024. Available at: https://workofthefuture-taskforce.mit.edu/mission/
Author’s note: The views expressed in the article are those of the author and not of the organizations he represents.
About The Authors:
 Partha Anbil is at the intersection of the life sciences industry and management consulting. He is currently an industry advisor, life sciences, at MIT, his alma mater. He held senior leadership roles at WNS, IBM, Booz & Company, Symphony, IQVIA, KPMG Consulting, and PWC. Anbil has consulted with and counseled health and life sciences clients on structuring solutions to address strategic, operational, and organizational challenges. He was a member of the IBM Industry Academy, a highly selective group of professionals inducted by invitation only, the highest honor at IBM. He is a healthcare expert member of the World Economic Forum (WEF).
Partha Anbil is at the intersection of the life sciences industry and management consulting. He is currently an industry advisor, life sciences, at MIT, his alma mater. He held senior leadership roles at WNS, IBM, Booz & Company, Symphony, IQVIA, KPMG Consulting, and PWC. Anbil has consulted with and counseled health and life sciences clients on structuring solutions to address strategic, operational, and organizational challenges. He was a member of the IBM Industry Academy, a highly selective group of professionals inducted by invitation only, the highest honor at IBM. He is a healthcare expert member of the World Economic Forum (WEF).
 Partha Khot is the life sciences practice lead at Coforge, a $1.7B multinational digital solutions and technology consulting services company focused on driving innovation at the intersection of domain and technology. He held leadership roles at Triomics, Abbott, and Citiustech, driving healthcare innovation and consulting across the U.S., Europe, and India. Partha is responsible for developing next-generation life sciences solutions at Coforge, built on industry platforms and differentiated through AI/automation accelerators.
Partha Khot is the life sciences practice lead at Coforge, a $1.7B multinational digital solutions and technology consulting services company focused on driving innovation at the intersection of domain and technology. He held leadership roles at Triomics, Abbott, and Citiustech, driving healthcare innovation and consulting across the U.S., Europe, and India. Partha is responsible for developing next-generation life sciences solutions at Coforge, built on industry platforms and differentiated through AI/automation accelerators.